![]()
2016/02/26
3章では、従来の機械学習とディープラーニングの違いについて説明しました。
特に特徴量の設計が大きな違いでありこれを機械自ら出来つつあること、また、学習するためにはデータが重要であることも説明しました。
3章では画像認識という例から違いを見ましたが、人材紹介においてはどんな変化が起きるのでしょうか。
従来の機械学習による人材紹介、ディープラーニングがもたらす変化、変化が起きた場合に何が重要かを見ていきたいと思います。
従来の機械学習では特徴量の設計、マッチング精度に限界がある
現在、機械学習を用いた人材紹介サービスには様々なものがありますが、ここでは株式会社ビズリーチのキャリアトレック[3]と、株式会社ブレインパッド・株式会社アトラエの共同開発によるTalentBase[4]において、どのような特徴量を用いているか見ていきます。
またTalentBaseについては、株式会社アトラエ取締役の岡様のインタビューを踏まえた上で書かせて頂いております。

キャリアトレックとはレコメンド型転職サイトであり、30万人の求職者のデータのノウハウと経験を基に、転職者に求人を推薦します。
イメージとしては、通販のレコメンド機能と同じです。求職者が勧められた求人を見て、興味があればエントリーをし、興味がなければ無視します。機械はその判断を記録し、求職者が興味のある求人の特徴を学習していきます。
よって求職者が使えば使うほど、データは蓄積されるので、レコメンドの精度は上がるというシステムになっています。
ではキャリアトレックでは何を特徴量として設定しているでしょうか。キャリアトレック[3]によると、レコメンドエンジンでは以下の4つを用いており、これらを基に特徴量を抽出していることがわかりました。特徴量は「経験」「業種」「スキル」「アンケートからの求められる志向性」「行動履歴」などとなります。
①、②は求職者が回答することによって得られるデータです。③、④は求職者が利用することによって自動的に得られるデータです。
これらのデータを入力とし、エンジニアが設計した特徴量を基に推薦する求人を選んでいることがわかります。
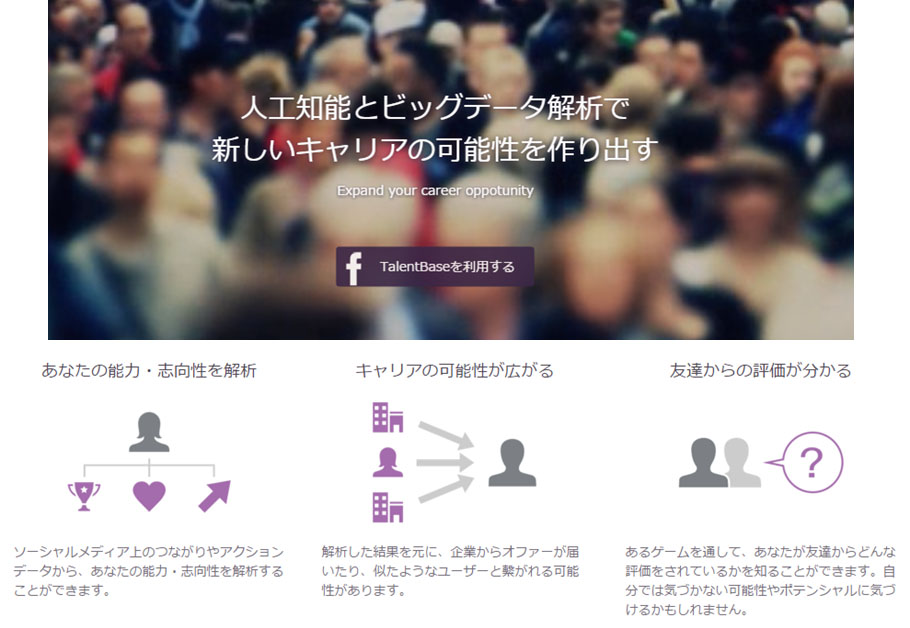
TalentBaseは約500万人のソーシャルデータを活用し、人工知能によって企業が求めるタレント(人材)のプール(母集団)を自動で生成・管理する画期的な採用サービスです。
具体的には、企業がサービス上でフォルダを作り、そこに企業が求めるサンプルとなる人材を入れ、その人材の特徴を基に人工知能が人材をレコメンドします。そして企業側がそのレコメンドに対しOKかNGを示すことによって、人工知能のレコメンド機能は学習していきます。
開発の動機としては「採用の形にもっと別の形があっても良いんじゃないか。」という意識があり、履歴書では表せない人間関係や志向性を可視化したいという狙いがあるそうです。
データはユーザがFacebookから登録を行うことで、Facebook上での投稿や友人関係、プロフィール等取得し、判断ルールを生成しています。
具体的には投稿の単語を抽出し、その人の特徴を単語で表現します。そこから似た単語を使っている人は相関が高いとし、グループ分けをしています。また「いいね!」や「シェア」「コメント」からもユーザがどういうものに興味があるのかを解析しています。よって特徴量は投稿や友人関係などの「ユーザのFacebook上での活動履歴」「ユーザの経験職種などの基本情報」などとなります。
精度が気になるところだと思いますが、これは職種によるみたいです。エンジニアや経営者、人事などは投稿や友人関係の特徴が似ており(相関が高い)、グループ化をし易いためレコメンドの精度は高くなるそうです。
一方、営業や総務などは特徴が多岐にわたるため、一概にグループを分けられず、精度は中々上がりづらいそうです。
また、課題としてはデータ量とデータ密度があるそうです。やはりデータが少なければ精度も上がらない、また特徴を100個設計しているのに50個しかデータが無く密度が低いと精度が上がらないということがあるそうです。
この課題の解決策として、データがわからない部分の代わりとなるデータを設計すること、他サービスを展開することで人間関係などのデータ量を増やすことを行っているそうです。
しかし機械学習における人材紹介マッチングは精度を考えると、限界があると考えられます。その理由を以下に示しますが、ここでは信頼や安心感などの人間同士の接触による価値提供の観点は考慮せず、マッチングの精度(内定に繋がるか)という観点から考えています。
こういった点から、従来の機械学習によるマッチングの精度には限界があると考えられます。
業務効率向上~人工知能によるマッチングまで、可能性は無限大!?
上記では、従来の機械学習におけるサービスの紹介と限界を説明しました。ではディープラーニングを用いて「機械自ら特徴量を設計」することにより人材紹介はどう変わる可能性があるのか。実現可能かどうかは考慮せずに様々な仮説を立て、自分なりに考察していきたいと思います。
これは営業が既に求人を獲得しており、そこから人の介入が入らずにマッチングを行うパターンです。
よって人材紹介会社の社員は営業、運用担当等の最低限になるということがありえます。イメージはPepperが外部との接触(面談)を担当し、ディープラーニングを持つ人工知能がマッチングを行います。キャリアコンサルタントは経験を重ねる毎に「この求職者・求人は前回のあの感じに似ているな」等の勘が養われていくと思います。これは過去のマッチング経験がデータとなり、そこから判断ルールが生まれていると考えられます。そのデータは
が考えられます。
このデータを人工知能にインプットすることでマッチングを行います。
①は履歴書をテキストデータとして正確に表現しフォーマットを統一し、ディープラーニングにより特徴量を抽出した後、求職者を分類(営業経験者、営業と経営企画経験者など)します。
また、求人においてもフォーマットを統一させ、正確にテキストデータにすることで、人工知能が分類を行い、マッチングを行います。
②はリクルートのSPIのようなものでデータ化することでマッチングをします。
求職者の今後どうなりたいかという志向性はSPIのような性格診断とこれまでの経験の掛け合わせにより表現が出来ると仮説を立て、そこから求職者を志向性で分類します。また企業においても人の集まりのため、同様にそこで働く社員のデータを取ることで、分類されます。
この2つのデータにより志向性のマッチングが出来るのではないでしょうか。
③はディープラーニングが今後進化した先に可能性があるかもしれません。
画像認識ができ、現在のディープラーニングは赤ちゃんのような状態です。今後はロボットと連動し、実際に体を動かすことで画像認識以上の概念を習得していき(猫は毛があり、暖かいなど)、人間と同じような成長の仕方をすると言われています。また、Pepperを面談に同席させることで、求職者の表情の読み取り方や質問の仕方を学習していき、面接のフォローアップも可能になるかもしれません。
よってPepperのような外部と接触する機械が学習すると、人間に近い感覚を得ることができ、最終的には人間同様のことが出来るかもしれません。
アナログ情報のマッチング(社風や志向性)や面接のフォローアップはキャリアコンサルタントが行い、履歴書上のスキルや経験のマッチングは人工知能が行うパターンです。
求職者の能力やスキルは仮説1の①と同様にマッチングを行うことが出来ます。
このマッチングを人工知能が行うことで、キャリアコンサルタント毎による認識の差や、情報量の減少(同じ求職者に対し面談はAさんが行ったが、紹介はBさんが行う際の情報伝達ミス)という問題は無くすことができ、マッチング水準を一定に保つことが出来ると考えられます。
人工知能がマッチングを行い、その求職者にオファーを送り、その後の面談でキャリアコンサルタントがアナログ情報を考慮し判断し、面接のフォローアップまでを行うというのが考えられます。
キャリアコンサルタントは面談前に求職者の履歴書を基に自社のデータベースに登録できるか、紹介できる求人があるか、ということを判断します。この判断を人工知能が行うパターンです。
この判断は人間によっては着眼点が多少異なり、会社全体として均一に判断を出来ていない可能性があります。よって過去の求職者のデータを基に、人工知能に自社で登録をする求職者のタイプを学習させておくと、判断レベルを均一に保つ事ができると思います。
そこからこれまで通り、キャリアコンサルタントがマッチングを行うという流れです。
転職・採用では求職者・企業共に現状以上を望んでおり、上手く行かないケースがあります。この期待値が高いことを調整するのを「期待値調整[5]」とします。[5]の記事から期待値調整の説明を一部引用します。
転職者は自らの相場よりもずっと高い企業や職種、例えば、大企業や新規事業や経営企画などに転職できることを期待している。また、企業は自らの相場よりもスペックの高い人材を低所得で雇えることを期待している。
この期待値調整の補助を人工知能が行うパターンです。求職者・企業共に現状以上を望んでいるということは、その現状を分かってもらう必要があります。
そこで求職者の転職成功データと企業の採用成功データを基に成功例を分類します。そうすることで新しい求職者や企業は過去のデータからこういった会社に転職出来る・こういった人を採用できると事前に伝えることが出来ます。そこで両者の期待値を予め調整しておくことで、採用の成功率は上がるかもしれません。
問い合わせのある求人に対してキャリアコンサルタントが割り振られますが、これを人工知能が行うパターンです。
キャリアコンサルタントの中でも、「この案件はあの人なら決められるだろう」というのがあると思いますが、これを人の主観ではなく、人工知能が行うことが出来ると思います。
キャリアコンサルタントと採用成功をさせた求人をデータとして与えることで、人工知能は自動的にその特徴を見つけ、キャリアコンサルタントの得意な求人を分類します。新しい求人があったらどこに当てはまるか判断し、キャリアコンサルタントに割り振ります。
これが出来れば求人の決定数も上がると思われます。
これはディープラーニングを使う必要はないかもしれません。マッチング関係はキャリアコンサルタントが行い、事務作業を人工知能が行うパターンです。
人材紹介において、日程調整や面接後の報告などは電話やメールで行われます。しかし電話が繋がらない、メールを見ていない等、時間を多く取られる業務でもあります。
よってこういった事務作業を人工知能が行うことで、キャリアコンサルタントは本業のマッチングや営業、面談を行うことが出来ます。人工知能は人間の業務効率を上げるアシスタントとなる存在になるかもしれません。
![]()
 ヘッドハンティング会社から電話があったときに確認す...
ヘッドハンティング会社から電話があったときに確認す... 3大メガ時代でどうなる損害保険業界?損保業界研究レ...
3大メガ時代でどうなる損害保険業界?損保業界研究レ... 人材紹介業の動向、大手・中小人材紹介会社の今後とは...
人材紹介業の動向、大手・中小人材紹介会社の今後とは... 日立 東芝 三菱重工業から見る日本の重電業界...
日立 東芝 三菱重工業から見る日本の重電業界...Talk Geniusとは-
ヘッドハンティング会社のジーニアスが提供する人と会社と組織を考えるニュースマガジンです。